CPU: el cerebro general
Ejecuta el sistema, apps y lógica secuencial.
Hardware explicado sin vueltas: qué comprar, por qué, y cuánto rinde.
Lo esencial y su rol cuando hablamos de IA y datos.
CPU, NPU e iGPU: roles complementarios

La respuesta de AMD para notebooks con IA integrada (2024/25), mezclando núcleos Zen y una NPU XDNA 2.
CPU (mixta)
NPU (XDNA 2): ~50 TOPS y soporte BF16; matriz de “tiles” con SRAM local y DMAs para mover datos con muy poco consumo.
Gráficos: iGPU RDNA 3.5 (Radeon 800M), útil para IA por GPU y juegos ligeros.
Por qué importa para IA: más hilos de CPU ayudan en pre/post‑proceso (tokenizar, compresión, I/O); la NPU toma el “matmul” repetitivo; la iGPU acelera cargas grandes optimizadas para GPU.

El chip de Intel para notebooks finas de 2024/25, con dos tipos de núcleos y una NPU nueva (NPU 4).
CPU (híbrida)
Ejemplo tope: Core Ultra 9 288V: 8 núcleos/8 hilos → 4 P‑cores (Lion Cove) + 4 E‑cores (Skymont).
NPU: hasta ~48 TOPS para inferencia local (traducción en vivo, efectos de cámara, subtítulos) sin agotar batería.
Gráficos: iGPU Xe2‑LPG (Battlemage) para 3D e IA por GPU cuando conviene.
Memoria: LPDDR5X soldada en el paquete para menor latencia y consumo (beneficia CPU, iGPU y NPU).
Por qué importa para IA: si parte del modelo no entra en la NPU o requiere otra instrucción, la CPU lo toma; si es muy paralelo/gráfico, la iGPU ayuda. Combina baja latencia y buena autonomía.


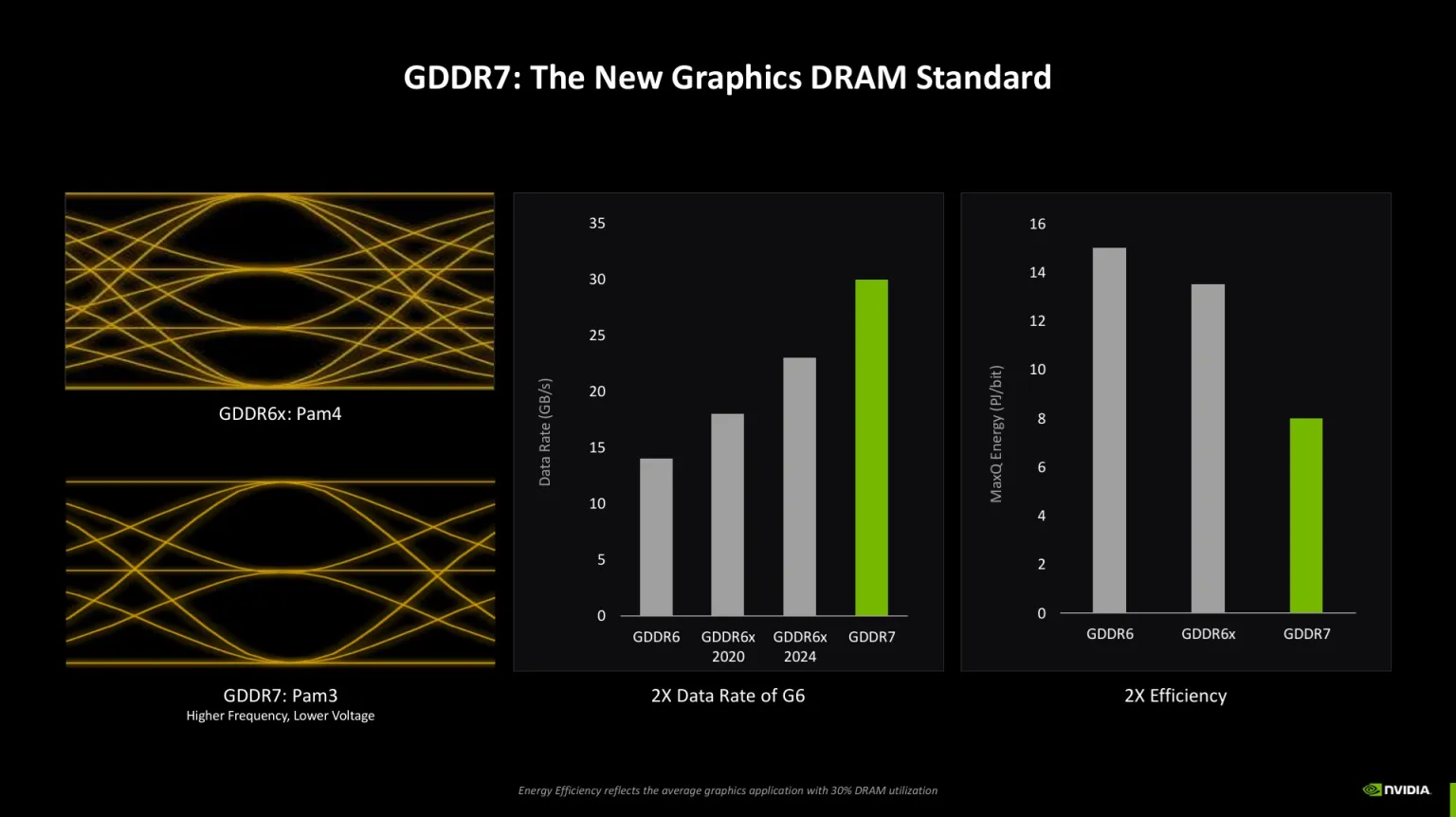
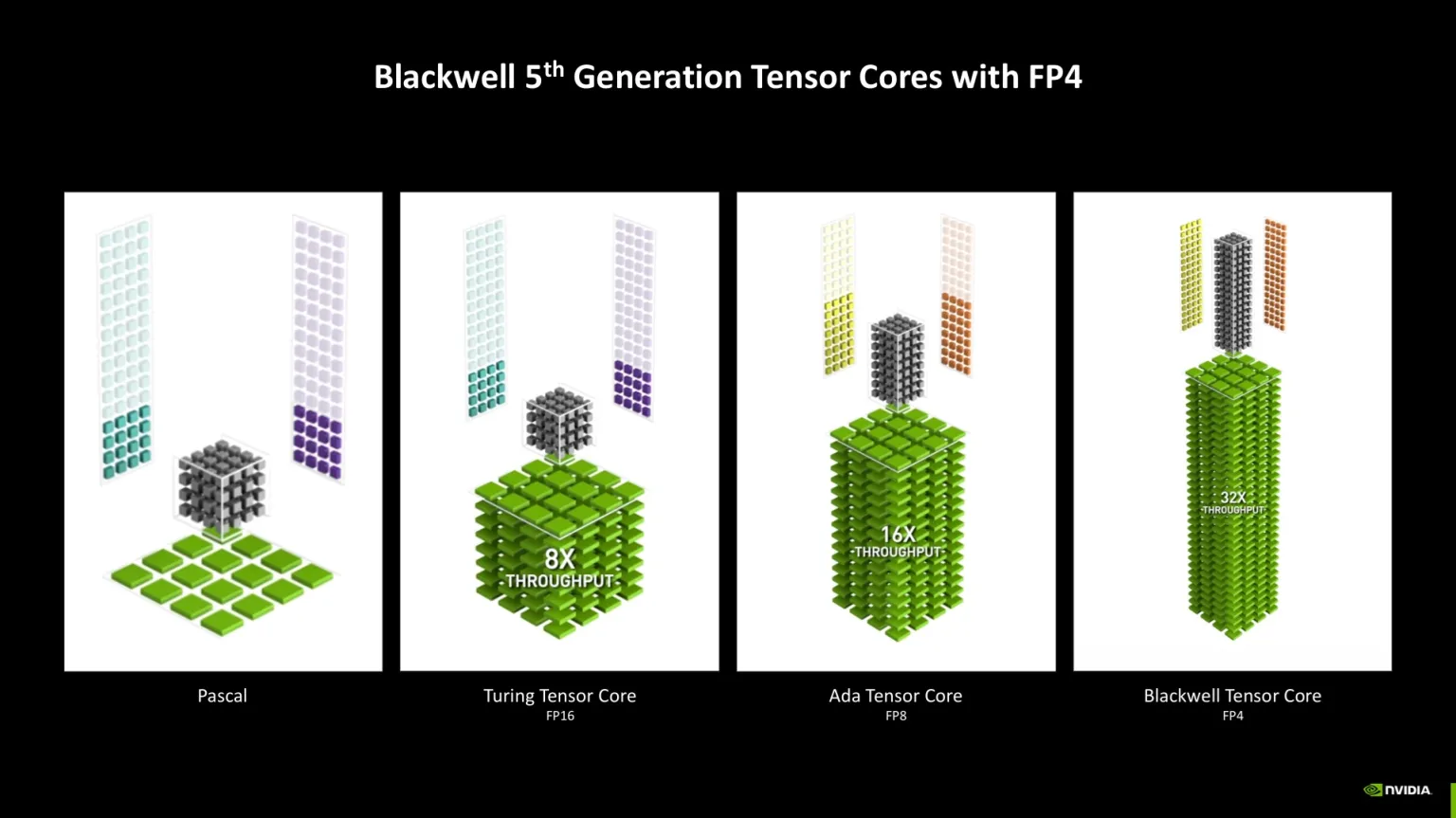
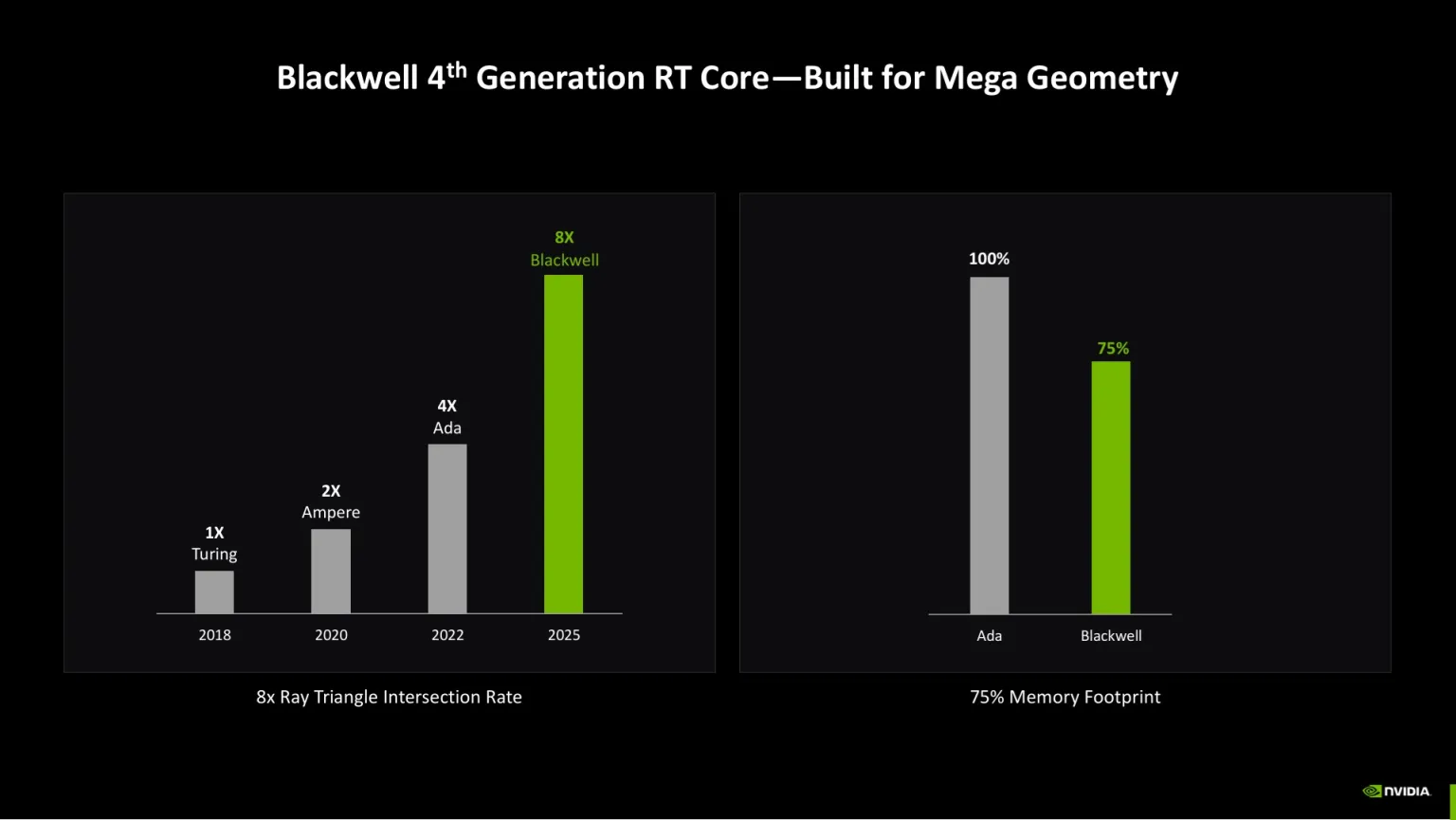



La RTX 5090 es tope de gama: paralelismo masivo con 32 GB GDDR7 y hardware dedicado para IA y ray tracing. Permite modelos grandes, lotes altos y edición/juegos a resoluciones muy altas.
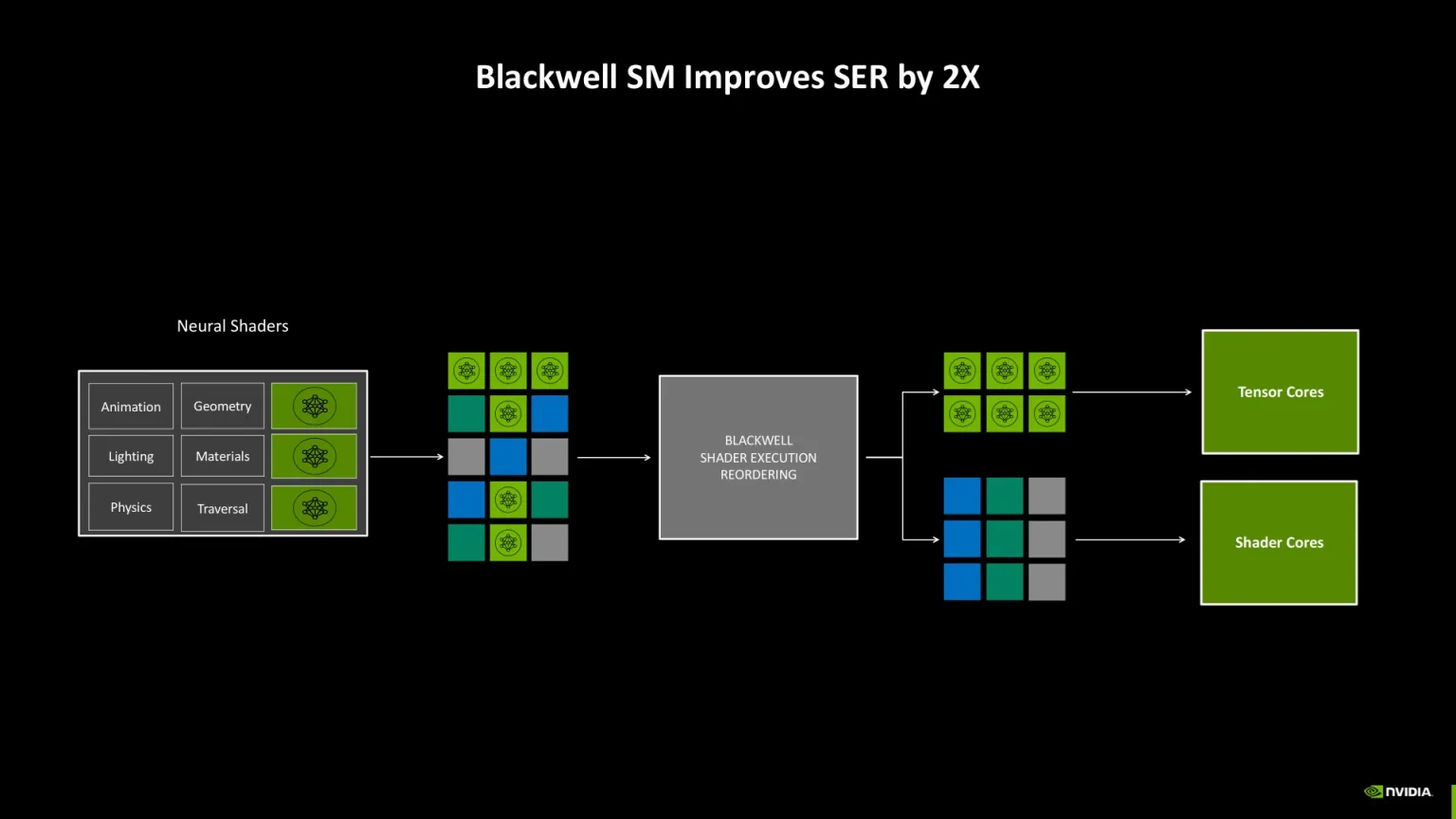
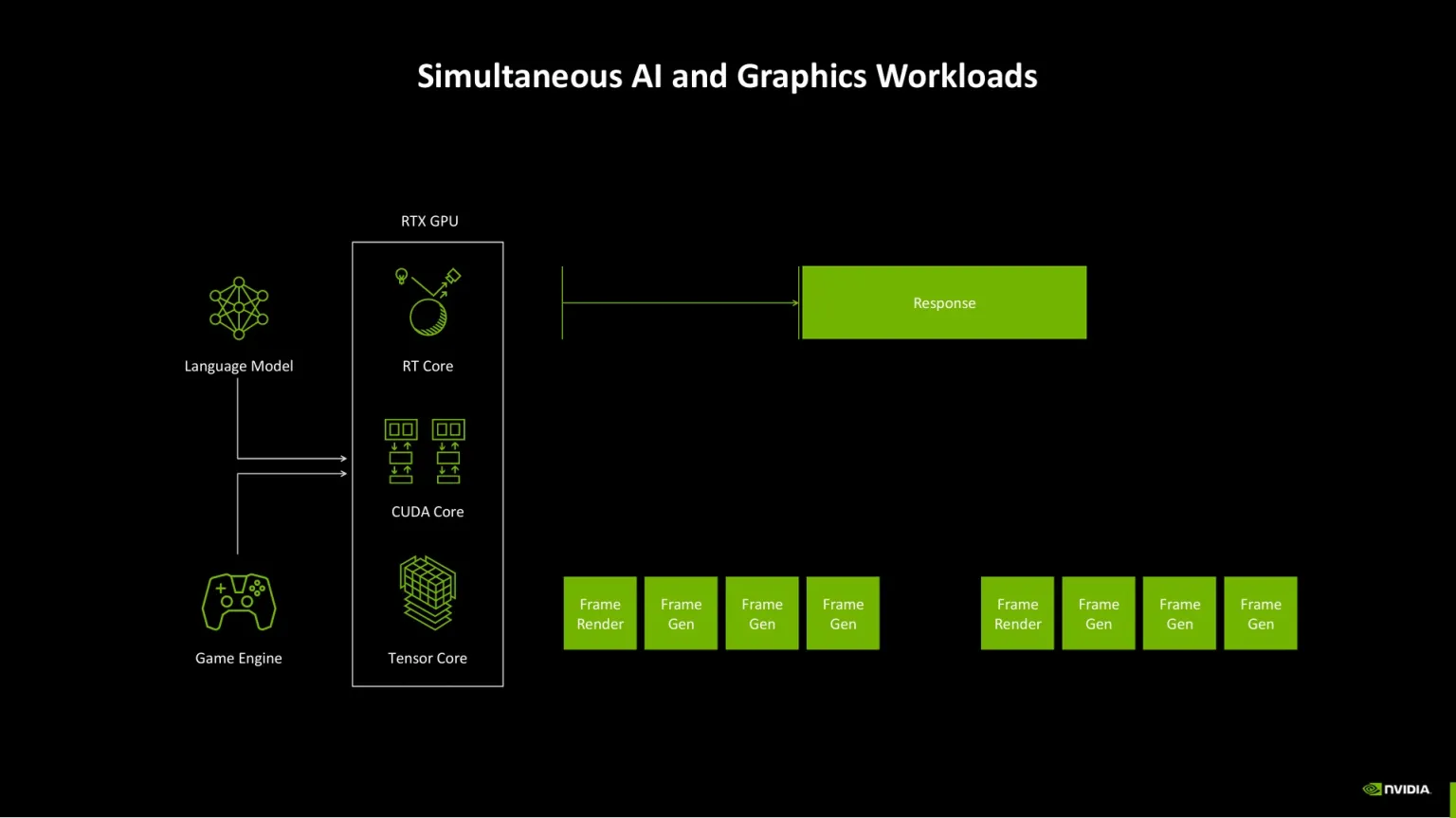
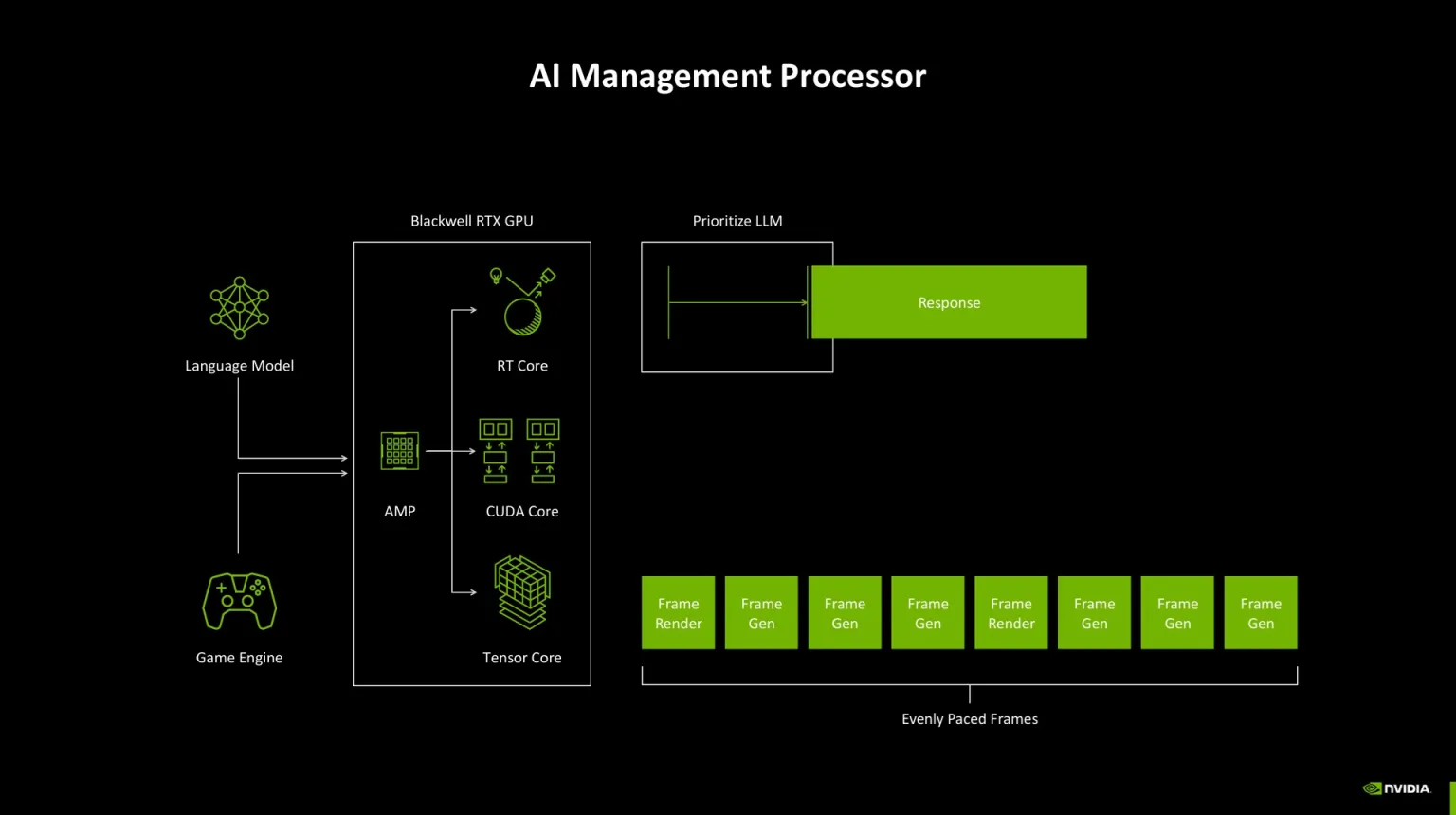
El “AI Management Processor (AMP)” orquesta tareas dentro de la GPU: prioriza la respuesta del modelo y ordena el render para frames estables. Sin AMP, IA y gráficos compiten por recursos y puede haber picos de latencia.
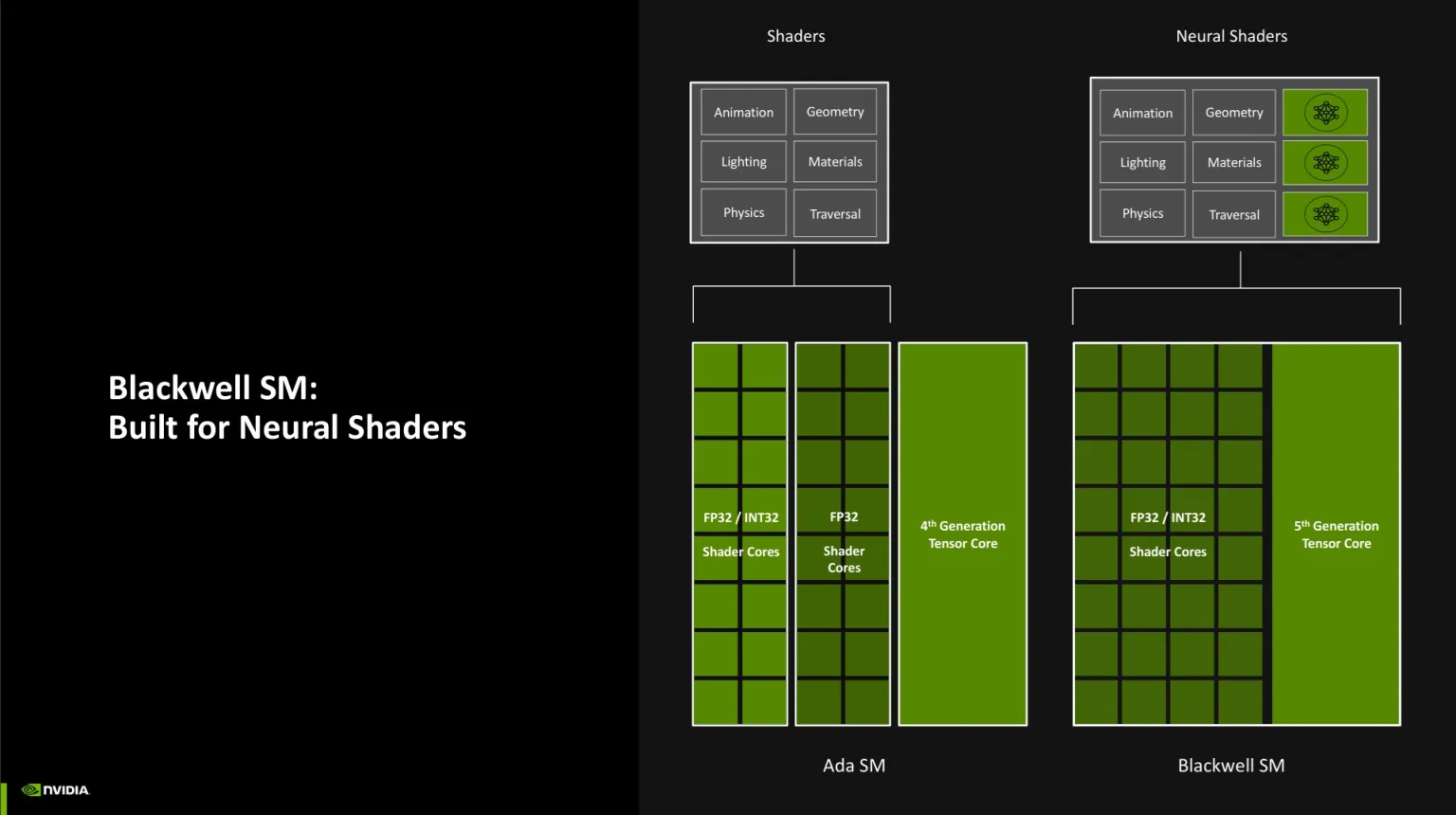
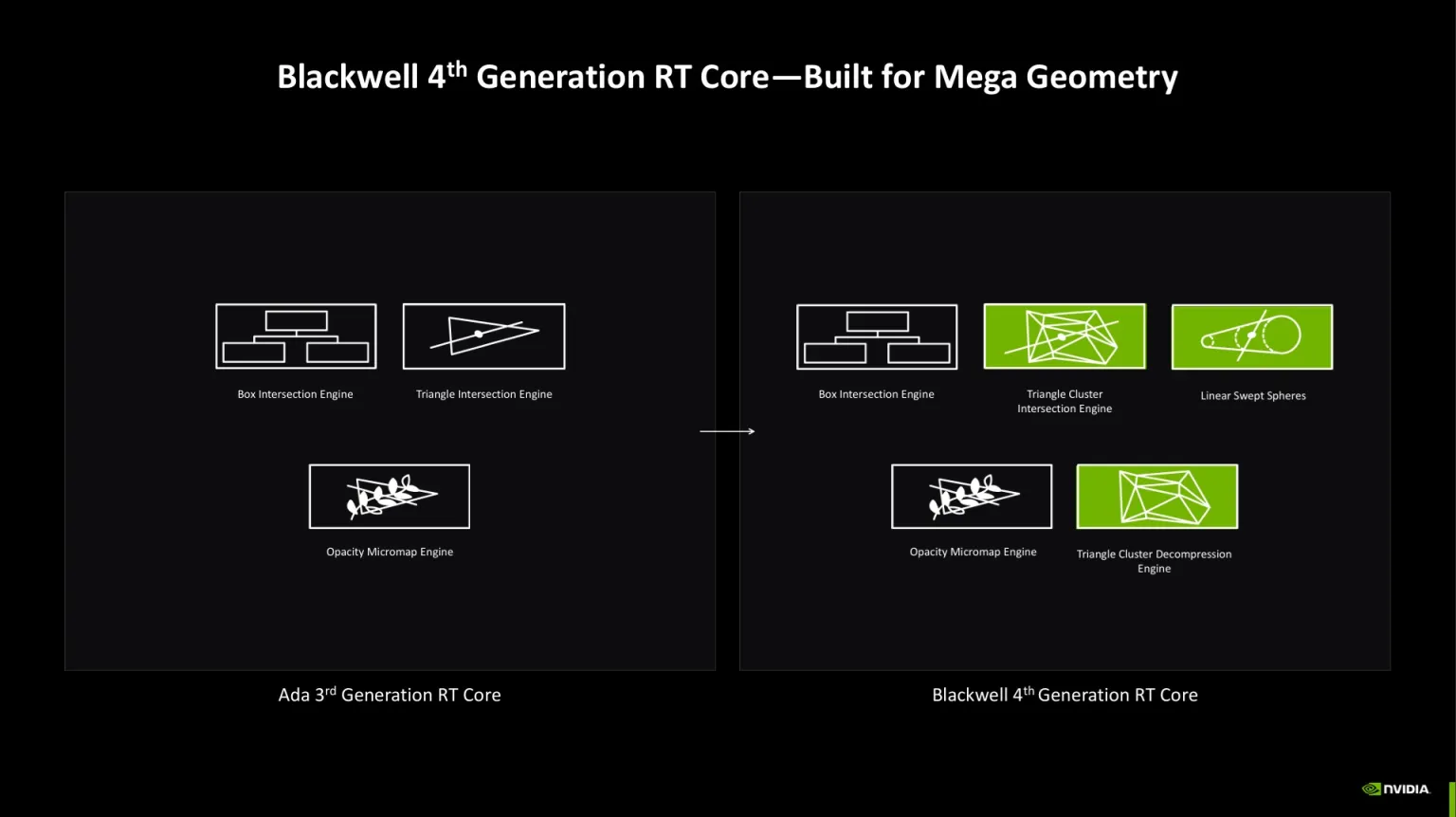
El SM Blackwell integra Tensor Cores de 5ª gen preparados para neural shaders (FP4/FP8/FP16) con gran rendimiento por vatio en IA.
Resumen: Tensor Cores para redes, RT Cores para geometría, AMP para coordinar, y GDDR7 ultrarrápida alimentando todo: más calidad + más FPS con IA rápida y frames estables.
¿Qué son y por qué importa?
Un SSD usa memoria flash NAND para guardar datos de forma persistente y no tiene partes móviles, a diferencia de los HDD. Esto habilita mayor velocidad, fiabilidad y operación silenciosa.


| Tecnología | Comparación | Velocidad aproximada |
|---|---|---|
| SATA | Ruta de 2 carriles | Hasta 550 MB/s |
| NVMe | Autopista de 8 carriles | Entre 3000 y 7000 MB/s |
Para archivos grandes o IA, NVMe es como pasar de una moto en calle lenta a un F1 en pista libre.
Velocidad secuencial (MB/s)
Latencia (µs, menor es mejor)
Fuente: @benchmarker64
En escenarios de entrenamiento con millones de muestras:
| Característica | SSD SATA | SSD NVMe |
|---|---|---|
| Interfaz / Bus | SATA (AHCI) | PCIe |
| Velocidad máx. aprox. | Hasta 550 MB/s | 3.000–7.000 MB/s (según PCIe) |
| Latencia | Más alta | Muy baja |
| Colas de comando | 1 cola · 32 comandos | Hasta 65.535 colas · 65.536 comandos |
| Formato habitual | 2.5” / M.2 SATA | M.2 NVMe / U.2 / PCIe |
| Compatibilidad | Altísima | PCs modernas con PCIe/M.2 |
| Costo por GB | Más económico | Más caro |
| Uso ideal | Archivos, backups, uso general | Gaming, IA, bases de datos, cargas pesadas |
| Consumo | Bajo | Bajo – medio |
| Instalación | Cable SATA + energía | Directo M.2/PCIe |
| Capacidades típicas | 240GB – 4TB | 500GB – 8TB (+) |
| Limitaciones | Tope bus SATA (6Gbps) | No compatible con hardware muy viejo |
PCIe Gen5 duplica el ancho de banda de Gen4 (hasta 32 GT/s) y habilita lecturas ~2.5× más rápidas y escrituras hasta ~5× más rápidas que Gen4, logrando el SSD más veloz en PC hoy.
Ryzen serie 7000+ y Core 12ª–14ª soportan PCIe 5.0. Requiere motherboard compatible (AMD X670E/X670/B650E; Intel Z890/Z790/Z690). Verificar la placa específica.
API de Microsoft que aprovecha SSD NVMe y GPU-driven IO para reducir latencia y carga en CPU, y acelerar descompresión por GPU.
En IA: datasets gigantes cargan más rápido y se alimenta mejor a la GPU.
Una bestia para entreno y una opción económica.
| 🔧 Componente | Workstation Extrema | Equipo de Entrada (~USD 800) |
|---|---|---|
| CPU | Threadripper 7980X | Ryzen 5 5600 |
| GPU | 4× RTX 4090 24GB | RTX 4060 Ti 16GB |
| RAM | 256 GB DDR5 ECC | 32 GB DDR4 3200 |
| Almacenamiento | 4 TB NVMe Gen5 + 16 TB SATA | 1 TB NVMe Gen4 |
| Fuente | 2000 W 80+ Platinum | 750 W 80+ Gold |
Especialista en Modelos de Lenguaje
Dos configuraciones enfocadas en LLMs: una premium sin límites de presupuesto y una económica con la mejor relación costo/beneficio.
Especificaciones Premium · $18,000–22,000 USD
Especificaciones Económicas · ~$800 USD
| 🔧 Componente | Premium (Money is No Object) | Económico (El Punto Dulce) |
|---|---|---|
| CPU | Threadripper 7980X (64c/128t) | Ryzen 5 5600 (6c/12t) |
| GPU | 4× RTX 4090 24GB (96GB VRAM) | RTX 4060 Ti 16GB |
| RAM | 512GB DDR5 4800 (8×64GB) | 32GB DDR4 3200 (2×16GB) |
| Almacenamiento | 4TB NVMe Gen5 + 16TB SSD SATA | 1TB NVMe Gen4 |
| Placa Base | ASUS Pro WS TRX50-SAGE WIFI | ASRock B550M-HDV |
| Presupuesto | $18,000–22,000 USD | ~$800 USD |
La configuración
Ambas priorizan la VRAM por encima del resto: en ML moderno, la memoria de GPU es el recurso más escaso y valioso. Recomendación: comenzar con la económica y escalar a cloud para experimentos que excedan su capacidad local.
Cúbits semiconductores y la próxima era
Son bits cuánticos implementados en materiales semiconductores (como silicio) que aprovechan propiedades cuánticas para representar 0 y 1 al mismo tiempo. Buscan combinar escalabilidad de la industria del chip con el poder de la computación cuántica.
Entrenar = GPU. Inferencia liviana/ETL = CPU+RAM.
32–64 GB para empezar; 128 GB si vas fuerte con DB o VMs.